
Ben Wright, April 1st 2024
In part 1 of this series, I discussed the motivation for using machine learning to classify land cover types in Mountain Legacy Project (MLP) images and described convolutional neural networks (CNNs), the technology we use to implement automated classification. This follow-up article tackles some challenges in applying this technology to MLP images and what specific implementations of CNNs we are testing to work toward an optimal solution.
—-
As a machine learning dataset, the Mountain Legacy Project (MLP) images present us with many challenges. First and foremost, is a need for more training data. Manually classifying images is a careful process which can limit the collection of completed classified images. The lack of image diversity means the network can quickly become biased toward the small amount of data it is trained on. To compound this issue, many land cover classes need more representation in the training images and are difficult for the network to learn.
Historical captures are greyscale images, while repeat captures are colour images, meaning the two sets of images need different networks that require separate training. This further subdivides the available data. These images also contain variable scales. For instance, coniferous forest with their distinct tree shapes in the foreground of an image look very different to the dark and fuzzy carpet of distant forest.
Finally, these images are very high resolution with pixel counts in the tens of millions. An entire network of information about them cannot be held collectively in the memory of most computers. As a result, the images must be scaled to lower resolutions or divided into patches to be fed to CNNs, thereby removing data (pixels) or contextual information (spatial relation between patches).

This image demonstrates the variability in scales across a single MLP image. For instance, coniferous forest in the near foreground appears very different to that in the background.
Currently, we have a working prototype convolutional neural network, PyLC. Developed for the Mountain Legacy Project by Spencer Rose and described by him in this post, can be used to classify images. This is a first iteration, and was meant to be primarily a study, and proof of concept. It has clearly proven to us that using Machine Learning to classify MLP images is feasible and exciting, but it is not a perfect solution.
To get around the roadblock of being unable to process complete images in the computer’s memory during training due to their size, PyLC subdivides images into smaller tiles to be processed separately, and these tiles are stitched together to form a final mask. This tiling allows all of the pixel information in the input image to be used, but the tiles are not contextually aware of each other.
The stitching of these images by PyLC often causes edge effects where two tiles meet, and often manifests as sharp, vertical, or horizontal artifacts in the output mask. Because each tile is treated sequentially by the network during classification, the process can also be slow and computationally intensive to produce classified masks. These limitations, along with poor performance, identifying some land cover types, especially in historical images, are the motivation for me and Aniket Mahindrakar – two research assistants with MLP – to work to improve upon the groundwork laid by Spencer Rose.

The land cover class mask produced by PyLC using the image above. The bottom right corner shows a stark example of several sharp vertical and horizontal class boundaries caused by stitching tiles.
New Models and New Strategies
We are now in the process of testing different CNN model architectures – essentially different arrangements of artificial neurons – to see what responds well to the MLP data. Several state-of-the-art architectures published in recent years make use of a promising context-aware approach to solving tiling issues in ultra-high resolution images. Two examples which we are testing, GLNet and FCtL [1,2], use local patches cropped from the image like PyLC, but in addition larger patches (or full images) providing greater context are cropped and then downsampled to a lower resolution and passed through a second branch of the network. Results of both branches, one aware of all pixel information and the other aware of greater spatial information, are then combined to form a prediction.
ISDNet, which we are also implementing, takes a slightly different approach to the same challenge, instead passing the full resolution image to a shallow branch of the network with fewer neurons to extract spatial features, making it easier to fit into memory, while passing a smaller downsampled version of the image to a deep branch to extract segmentation information. Again, the results of the two branches are combined to form a prediction.
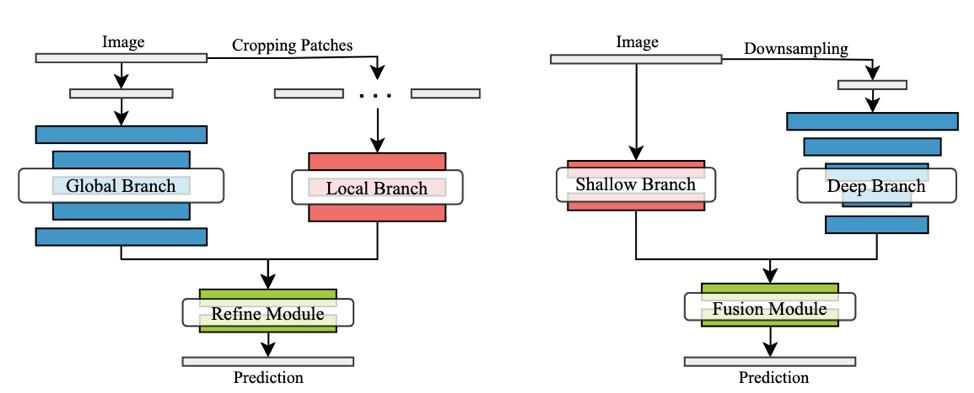
Two strategies for segmenting ultra-high resolution images. On the left is the context-aware global and local approach taken by FcTL and GLNet and on the right is the integrated shallow-deep branch approach of ISDNet. Testing has thus far shown that the global-local branch strategy preforms poorly on the MLP dataset. Both GLNet and FCtL do not adequately learn from the training data and fail to capture the necessary level of detail to produce usable land-cover masks. It is difficult to isolate a single reason for an architecture failing with a particular dataset. Still, the downsampled global context branches seem to override the fine details captured by the local branch and cause a loss of spatial resolution in the predictions. ISDNet shows more promise and, after our first test, performs nearly as well as PyLC but does not quite match it, while not suffering from the same degree of tiling problems. That gives us an exciting avenue to continue exploring and a lead on what direction to look for even better performing models
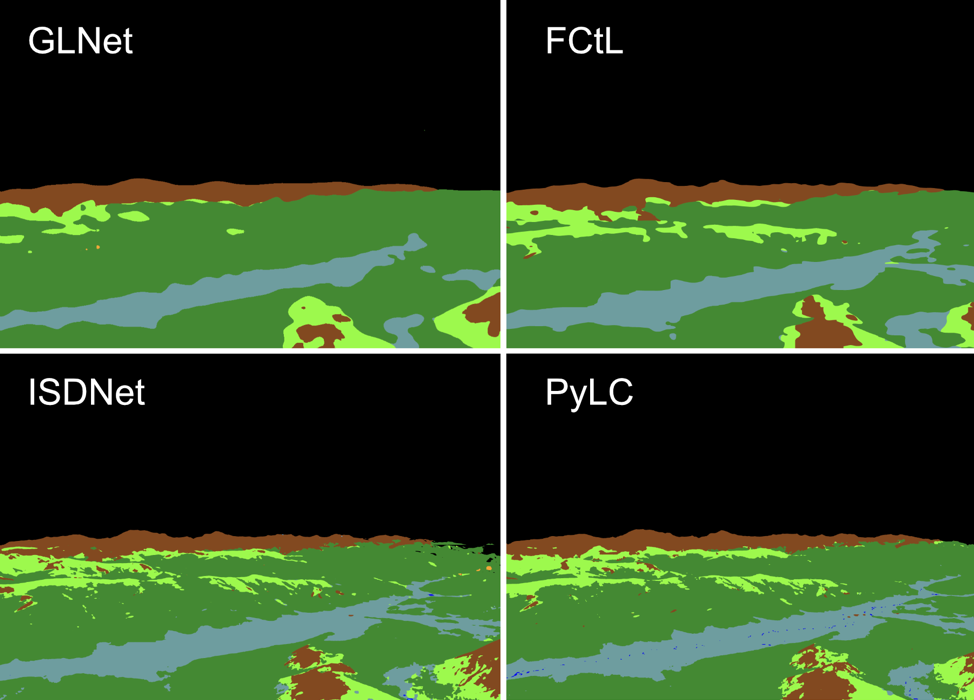
A comparison of landscape cover masks produced using the same reference image by different network architectures. The global-local context architectures (GLNet and FCtL) are not capturing sufficient levels of detail.
Simultaneously, we are testing new strategies beyond model architecture to improve predictions. Data augmentation techniques, for example, allow us to increase the representation of infrequent land cover classes in the dataset to reduce the imbalance between classes seen by the model during training and improve performance. This is already implemented by PyLC but we are exploring generative AI to increase and enhance our ability to augment the dataset. We are also studying methods to reduce the effects of tiling using novel probabilistic stitching algorithms.
Finally, to help improve the lack of data, we are constantly working to produce and incorporate as many manual land cover masks as possible into the training dataset. In these ways, we are working to overcome the challenges posed by the MLP dataset for use with a CNN and striving toward the ability to consistently generate high-quality land cover masks without long hours of manual annotation.
[1] W. Chen, Z. Jiang, Z. Wang, K. Cui and X. Qian, “Collaborative Global-Local Networks for Memory-Efficient Segmentation of Ultra-High Resolution Images,” 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 2019, pp. 8916-8925, doi: 10.1109/CVPR.2019.00913.
[2] Q. Li, W. Yang, W. Liu, Y. Yu and S. He, “From Contexts to Locality: Ultra-high Resolution Image Segmentation via Locality-aware Contextual Correlation,” 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 2021, pp. 7232-7241, doi: 10.1109/ICCV48922.2021.00716.
[3] S. Guo et al., “ISDNet: Integrating Shallow and Deep Networks for Efficient Ultra-high Resolution Segmentation,” 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 2022, pp. 4351-4360, doi: 10.1109/CVPR52688.2022.00432.